세타원, AI 전쟁터(?) ACL 2025에 가다.
멀티모달 AI를 통한 교육의 혁신을 꿈꾸는 세타원 AI가 자연어처리 분야 최고의 국제 학회로 꼽히는 ACL 2025에 다녀왔습니다.
전 세계에서 무려 8,360편의 논문이 투고된 이번 학회를 통해 새삼 AI에 대한 관심과 열기를 느낄 수 있었는데요. 세타원 AI의 멀티모달 AI 연구·개발을 책임지는 Gio님의 ACL 2025 참석 후기를 공유드립니다.
본문에 앞서, Gio님이 참여한 논문도 공유드려요! ✨
MMRefine: Unveiling the Obstacles to Robust Refinement in Multimodal Large Language Models
Paik et al., Findings of the Association for Computational Linguistics, 2025
안녕하세요! 세타원의 스피치 AI 연구·개발을 맡고 있는 ML Engineer, Gio입니다. 😎
7월 27일부터 8월 1일까지 오스트리아 비엔나에서 진행된 ACL 2025에 참석하여, 국내외의 다양한 연구 결과를 접하고 전 세계의 연구자분들과도 소통하는 뜻깊은 시간을 가질 수 있었습니다. 이 포스트에서는 아래의 목차로 ACL 2025 참여 후기를 간략히 공유드리고자 합니다.
- What is ACL?
- Papers in ACL 2025
- Poster Presentation
- Beyond ACL 2025

🤔 What is ACL?
ACL은 Annual Meeting of the Association for Computational Linguistics의 약자로, 직역하면 **"전산 언어학에 대한 연례 학술회의"**를 의미합니다.
'전산 언어학'이라는 이름에서 알 수 있듯이, 컴퓨터를 이용하여 언어와 관련된 연구를 수행하는 학자들이 모여 연구 결과를 공유하고 아이디어를 나누는 행사인데요. 최근 몇 년간 큰 주목을 받고 있는 인공지능(AI), 그중에도 언어와 관련된 인공지능에 해당하는 GPT, Gemini와 같은 자연어 처리(NLP) 분야는 물론, 검색이나 번역, 감성 분석 등 그야말로 컴퓨터+언어와 관련된 모든 분야를 총망라하는 세계에서 가장 큰 규모의 AI 학회 중 하나입니다.
수많은 논문이 투고되는 만큼 실제로 행사에서 발표될 논문을 선정하는 작업도 까다롭게 진행되는데요. (1) 2-4명의 전문가가 익명 처리된 논문을 꼼꼼하게 검토하는 동료 평가, (2) 동료 평가 내용에 대한 저자의 보충 실험 및 논문 내용을 전반적으로 평가하는 메타 평가, (3) 논문이 ACL에서 발표될 만한지 최종적으로 검토하는 최종 결정 단계까지 모든 단계를 통과한 논문들만이 3일간 진행되는 학회 본 행사에서 발표할 수 있게 됩니다.
이러한 논문 발표 이외에도 본 행사 전후로 특정 주제에 대하여 선정된 뛰어난 연구자가 진행하는 튜토리얼, 초청 연사, 네트워킹 행사를 비롯한 다양한 행사가 진행되어 스피치 AI는 물론, 다양한 분야의 AI 연구를 접할 수 있었습니다. 특히 행사 마지막 2일간 진행되는 워크숍에서는 음성 인식, 교육을 위한 AI를 주제로 해당 분야의 연구자들끼리 심도 있는 연구 공유가 가능했는데요, 세타원 AI가 지향하는 AI 연구 방향을 다시금 점검할 수 있는 좋은 기회가 되었습니다.
📜 Papers in ACL 2025
지난 수년간 AI 분야에 대한 관심이 급속도로 증가함에 따라, 올해 ACL에만 8,360편의 논문이 제출되고 3,091편의 논문이 심사를 통과하였다고 합니다. (main 20.3%, findings 16.7%) 이는 전년 대비 70% 증가한 수치이며, 게재된 논문의 51%는 중국, 18.6%는 미국, 3.4%는 한국인 1저자가 작성하였다고 하네요. (한국이 3등 맞습니다!)
가장 많은 논문이 발표된 분야는 NLP Application(자연어처리 활용, 13.1%) 과 Resource and Evaluation(자원 및 평가, 12.4%) 이었으며, Multimodality and Language Grounding(멀티모달 및 그라운딩)과 Efficient-Low-Resource Methods(효율적인 저비용 방법론)가 그 뒤를 이었습니다.
5일간 다양한 포스터 발표와 구두 발표를 들으며, 인상 깊었던 논문들을 간단히 정리해보자면 아래와 같습니다.
멀티모달
LLaMA-Omni2: LLM-based Real-time Spoken Chatbot with Autoregressive Streaming Speech Synthesis
오픈 소스 LLM인 Qwen2.5에 Speech Encoder와 Adapter, Voice Decoder를 추가하여 Speech-in / Speech-out의 Speech LM으로 만드는 방법을 잘 설명한 논문. 언젠가 Speech LM에 본격적으로 도전하게 된다면 참고할 만하겠다 싶네요.
Centurio: On Drivers of Multilingual Ability of Large Vision-Language Models
대규모 비전-언어 모델의 다국어 성능에 대한 분석.
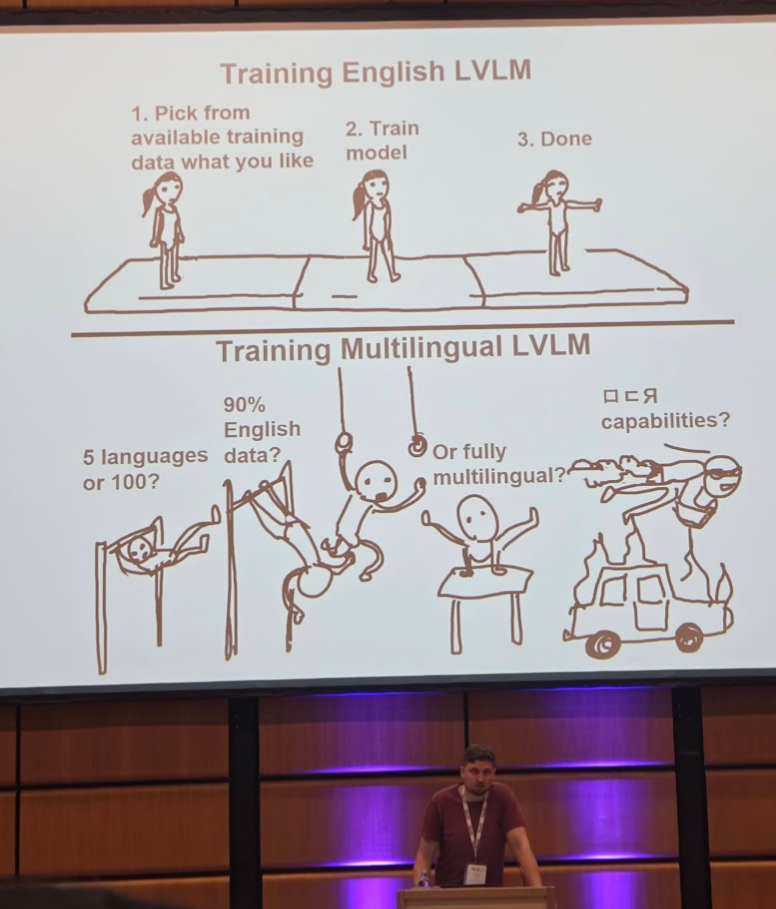
다국어 모델 학습 시에 영어 데이터 50%를 사용하고, 나머지 50%에 나머지 언어를 동등한 비율로 사용하는 것이 가장 좋았다던지, 특히 OCR의 경우에 multilingual data를 많이 넣어줘야 non-Latin 계열 문자 인식률이 오른다던지, 다양한 노하우가 담긴 알찬 발표였네요. 저는 개인적으로 Vision Language Model에 native OCR 능력을 기대하는 것이 지금 구조에서 올바른가에 대한 고민이 있기는 합니다.
From English to Second Language Mastery: Enhancing LLMs with Cross-Lingual Continued Instruction Tuning
Supervised Fine-tuning(SFT) 단계에서 번역된 instruction data로의 튜닝이 모델이 새로운 언어를 익히는 데 충분하다는 주장. 구체적으로 촘스키 교수님의 principles and parameters 이론에 빗대어, 인간이 모국어로 먼저 principles를 학습하고 외국어(parameters)를 학습하는 과정을 모사하여 continual instruction tuning을 하는 것이, 영어와 외국어 데이터를 섞어 처음부터 학습하는 것보다 좋다고 합니다. Speech Model에도 일반화될지 궁금하네요.
Code-Switching Curriculum Learning for Multilingual Transfer to LLMs
앞선 논문과 접근은 비슷한데, 코드 스위칭을 활용합니다. 사람이 몇 개의 단어부터 시작해서 다른 언어를 배우듯, 처음에는 학습 데이터에서 일부 토큰(단어)만을 외국어로 바꾸고 학습, token-level code-switching > sentence-level code-switching > monolingual (target language)로의 curriculum learning을 수행하는 것이 target language 성능을 높인다고 하네요.
ASR
Hypernetworks for Personalizing ASR to Atypical Speech
파킨슨병 등으로 비정형 발화를 하는 사용자들을 위해, 개인별로 모델 파인튜닝을 통해 맞춤 모델을 만드는 대신, 사용자 맞춤 가중치를 생성하는 하이퍼네트워크를 학습시켜 모델을 개인화하는 방식. 서비스 측면에서도 사용자별 가중치만 사전 계산해 저장해두면 되니 좋을 것 같네요.
SIFT-50M: A Large-Scale Multilingual Dataset for Speech Instruction Fine-Tuning
아마존에서 제작한 14,000시간짜리 5개 국어 스피치 데이터셋. 영어, 프랑스어, 독일어, 스페인어, 이탈리아어로 모두 서구권 언어로만 구성된 것은 아쉽네요. 그래도 가뭄에 단비 같은 스피치 데이터셋이라 그런지, 나오자마자 여기저기 쓰이는 모습입니다.
DNCASR: End-to-end Training for Speaker-attributed ASR
Speaker clustering과 ASR을 동시에 학습하고, 추론하는 End-to-end 모델 제안. STT 개발하는 입장에서 이런 연구 반갑더라구요.
Distilling an End-to-End Voice Assistant Without Instruction Training Data
자극적인 제목인데요, 스피치 데이터가 전혀 없어도 되는 것은 아니고, speech instruction + 정답 쌍으로 이루어진 데이터가 아니라 speech instruction만 가지고 학습을 할 수 있다는 내용입니다. speech instruction을 transcribe해서 text로 만들고, LLM의 답변을 정답 signal 삼아 학습하면 된다는 거죠. 어찌 보면 이미 LM에게 지식은 충분하고, speech라는 새로운 모달리티에만 적응하면 되니 굳이 고품질의 정답 label은 필요 없다는 합리적인 아이디어 같네요.
데이터 부족 언어에 대한 연구
인도를 비롯해서 중동아시아 지역을 중심으로 이런 연구가 많더라구요. 저희도 생각보다 잘 정리된 데이터는 많지 않다 보니, 관심이 가는 연구들이 많았습니다.
- IndicSynth: A Large-Scale Multilingual Synthetic Speech Dataset for Low-Resource Indian Languages
- A-TASC: Asian TED-Based Automatic Subtitling Corpus
- GigaSpeech 2: An Evolving, Large-Scale and Multi-domain ASR Corpus for Low-Resource Languages with Automated Crawling, Transcription and Refinement
- LLäMmlein: Transparent, Compact and Competitive German-Only Language Models from Scratch
영어 데이터 다수 + 다른 언어 MIX로 학습하는 게 어느새 규칙처럼 되어버린 세상에서 참 반가운 논문인 것 같습니다. 모든 데이터가 동일하다면 어떤 언어로 학습하는가에 따라 차이가 있을까? 라는 의문도 드네요. - HyperOFA: Expanding LLM Vocabulary to New Languages via Hypernetwork-Based Embedding Initialization
기타
제 연구 분야에 직접적인 연관은 없지만, 재미있게 봤던 연구들도 소개해 봅니다.
- Value Portrait: Assessing Language Models' Values through Psychometrically and Ecologically Valid Items
일명 AI MBTI..!는 아니고, AI의 가치관을 심리학적 이론에 근거해 분류해 봤다고 합니다. 사실 AI의 성격은 프롬프트에 따라, context에 따라 바뀌긴 할 텐데, 아무 context도 없는 상태에서의 캐릭터는 무엇이 좌우하는 걸까요? - Curriculum Debiasing: Toward Robust Parameter Efficient Fine-Tuning Against Dataset Biases
- Understanding Silent Data Corruption in LLM Training
Silent Data Corruption이 뭔고 하니, 모델이 예측에 실패했는데 종료 시그널을 return하지 않아서 hardware를 계속 점유하고 있는 상태라고 합니다. (최근 이슈가 된 gemini의 무한 자학 루프 등) 이런 case가 batch에서 한 샘플만 발생해도 전체 pipeline이 멈춰버리니 학습에 큰 비효율을 초래하는데, 이 문제에 대한 심층적인 분석을 해봤다고 하네요. - Learning to Insert [PAUSE] Tokens for Better Reasoning
o1 등장 이후로 추론 중간에 special token을 두어 reasoning을 개선하고자 하는 시도가 많았는데, 이 token을 사람이 임의의 위치에 넣어주기도 하고 다양한 방법들이 시도되었습니다. 이 논문에서는 학습 단계에서 log-likelihood를 이용해서 자동으로 삽입하던데, 단순하면서도 effective 하겠더라구요.
논문들 외에도, 한 번쯤 고민해봐야겠다 싶은 키워드들도 있었는데요.
- Alignment
사람이 바라는 것, 이로운 것과 LLM의 발전방향, 평가지표는 잘 일치(align)되어 있을까요? 초청 연사에서 이를 꽤 진지하게 다뤘었는데, 며칠 전 출시된 GPT-5가 벤치마크는 압도적으로 우세함에도 불구하고 GPT-4o 대비 답변이비인간적이다T같다는 평가를 받는 걸 보면 정말 생각해볼만한 문제인 것 같습니다. - Tokenizer-free LM
초청연사분께서 말하길, 다들 tokenizer는 '그냥 그렇게 작동하는갑다'하고 넘어가는 경향이 있다고 하시던데, 인정하지 않을 수가 없었습니다. 영어 대비 수배 더 비효율적인 tokenizer로 피해를 보고 있는 우리나라 사람들도 별로 무관심한데, 영어권은 오죽할까요. Tokenizer-free LM 연구가 조금씩 진행되고 있는데, Multimodal 분야에서 막 continuous token, tokenizer-free가 주목받는 걸 보면 아주 먼 나라 이야기는 아니겠다 싶습니다. - Mixture of Experts
제안된지는 오래되었지만, 이제야 업계 표준으로 자리잡고 있는 것 같습니다. 직관적이고 강력하지만, 공간복잡성 측면에서 좀 애매하긴 하죠. 제품 개발도 하다 보니 더 그렇게 느껴지는 것 같습니다.저희도 B200 같은 GPU가 있으면 편하게 느껴질까요?
나름 정리한다고 정리했는데도 논문이 많네요! 공유드리지 않은 논문까지 포함하면, 적어도 50편 이상은 읽어볼 논문이 쌓인 것 같습니다. 사실 요즘에야 많은 논문이 학회에 가지 않아도 온라인으로 공유되지만, 그럼에도 불구하고 전세계의 AI 연구자들과 한 자리에 모여 연구를 공유하고, 대화를 나누는 경험은 굉장히 즐겁고 영감이 솟아오르는 경험이었던 것 같습니다.
당장 세타원의 음성인식 제품이나 영어 교육 서비스에 도움이 될 만한 아이디어는 물론, 장기적인 로드맵 설계에도 도움이 되는 아이디어를 얻고, 국내외의 네트워크도 크게 확장할 수 있는 좋은 기회였습니다.
🍀 Poster Presentation
제가 지구 반대편 유럽까지 날아간 이유가 논문 읽기와 슈니첼 때문만은 아니죠. 대망의 3일차, 1시간 30분의 포스터 발표를 진행했습니다..!
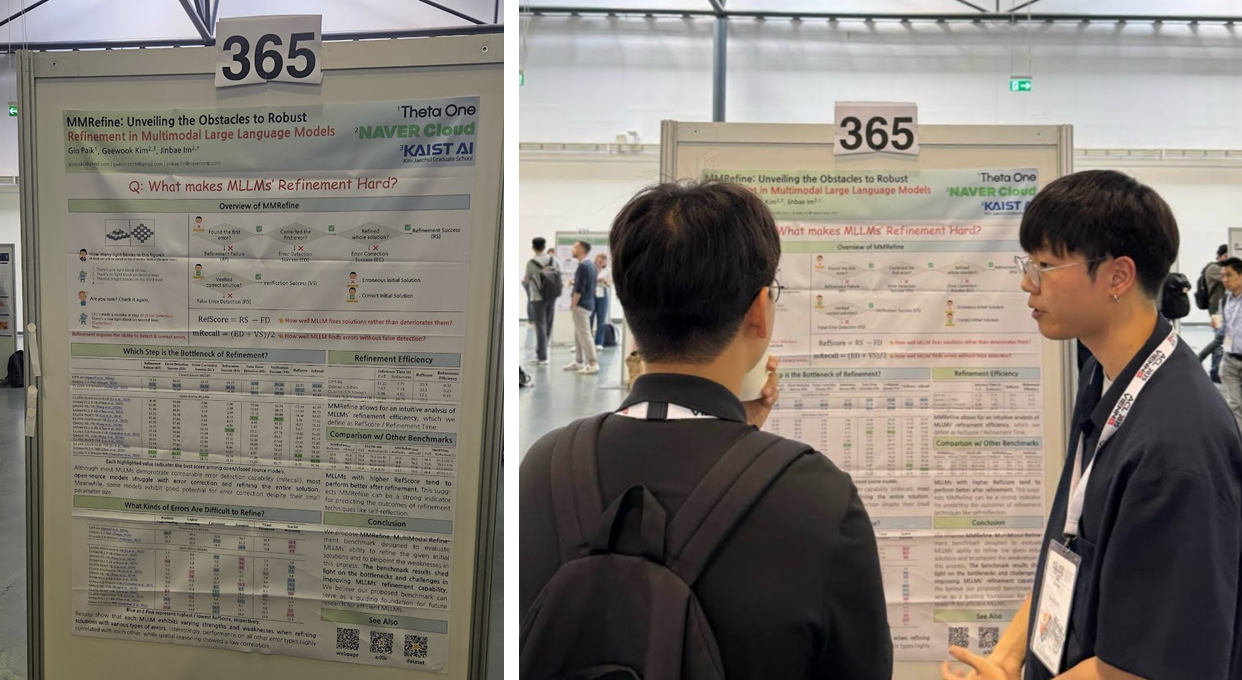
제가 발표한 논문은 멀티모달 언어 모델의 추론 개선(Refinement) 능력을 분석하고 평가하기 위한 벤치마크를 제안한 논문인 MMRefine: Unveiling the Obstacles to Robust Refinement in Multimodal Large Language Models인데요. 단순히 정확도만 비교해서는 알 수 없는 MLLM의 refinement 잠재력까지 확인할 수 있는 벤치마크에 많은 연구자분들이 관심을 가져주셨습니다.
세타원은 LLM, 음성인식 서비스 개발은 물론 멀티모달 언어모델 연구도 진행하고 있는데요. 발표를 찾아주신 분들의 "세타원은 뭐하는 회사인가요?"라는 질문을 들으며, 의미있고 뛰어난 연구를 통해 꾸준히 세타원의 mind share를 늘려가야곘다는 생각이 들었던 시간이었습니다.
🚀 Beyond ACL 2025
5일간 엄청난 규모로 진행된 ACL 2025를 참관하며, 새삼 빅테크 기업과 학계의 괴리가 피부로 와닿았습니다. 수년 전부터 발생하기 시작한 규모의 차이에 의한 연구 주제의 괴리 뿐만 아니라, alignment 문제나 generalization 문제와 같이 평가가 어렵고 모호한 영역에서 쌓여가고 있는 부채, scale up 일변도로 간과받는 다른 문제들(tokenizer 등)까지 많은 학자들이 문제를 공감하면서도 쉽사리 해결책을 내놓지 못 하는 상황이었습니다.
학자로서의 고민과 별개로, 학회에 참여한 굴지의 대기업들과 소규모 스타트업, industry track의 연구들을 살펴보며 세타원의 ML Engineer로서의 고민도 하지 않을 수가 없었습니다.
과연 스타트업이 추구해야할, 만들어야할 AI는 어떤 모습일까요?
역사가 채 10년도 되지 않는 ML Engineer라는 직업을 정의하는 요소는 무엇일까요?
이 질문들에 대한 명확한 정답은 회사에서도, 학회에서도 얻을 수 없었지만, 예로부터 Engineer가 해야할 일은 명징한 것 같습니다.
문제를 잘 정의하고, 기술이 그 문제를 해결할 수 있도록 하는 것.

세타원 AI는 AI 기술로 우리가 배우고, 소통하고, 즐겁게 사는데 필요한 문제들을 해결합니다.
우리는 좋은 것들-좋은 서비스, 유용한 오픈소스, 뛰어난 연구-을 만들며 나아갈 것입니다.
Theta One AI의 행보를 기대해주세요!
