한국어-영어 혼용 음성인식이 잘 안되는 이유
음성인식 모델을 한국향 서비스에 응용해보신 분이라면, Whisper를 비롯한 다국어 음성인식 모델이 생각보다 완벽하지 않다고 느껴보신 경험이 있으실텐데요.
특히, 외국어로 된 전문 용어가 사용되는 미팅이나 여러 언어를 섞어서 사용하는 다국어구사자의 음성인식 정확도가 유난히 떨어진다고 느끼셨다면, 정확히 보셨습니다!
세타원의 최신 연구 결과, 한국어나 영어 등 한 가지 언어만 사용되는 환경에서는 5% 미만의 아주 낮은 오류율을 보이는 음성인식 모델도, 한 음성에서 여러 가지 언어가 혼용되면 최대 14배까지 오류가 증가하는 것으로 드러났거든요!
오류가 5%대라고 해서 서비스에 적용했는데, 활용 분야에 따라서는 오류율이 60%까지 치솟아 도저히 사용할 수 없을 수도 있는 것이죠. 😱
이런 함정에 빠지지 않고 모델의 한국어-영어 혼용 (코드 스위칭) 음성인식 정확도를 정확히 측정하고, 나아가 모델의 성능 개선을 위한 방향성까지 제시하는 세타원 AI의 최신 연구 성과를 지금 공유합니다!
안녕하세요! 세타원의 스피치 AI 연구·개발을 맡고 있는 ML Engineer, Gio입니다. 😎
오늘은 세타원 AI에서 진행한 HiKE: Hierarchical Evaluation Framework for Korean-English Code-Switching Speech Recognition 연구 결과를 소개해드리고, 세타원 AI의 음성인식 기술도 간략히 소개드리려고 합니다.
이 연구에서 저희는:
- 한-영 코드 스위칭 음성인식 성능 평가를 위한 평가 프레임워크인 HiKE를 제안하고
- 이를 활용해 Whisper를 비롯한 다국어 음성인식 (ASR) 모델들의 한-영 코드 스위칭 오류율이 단일 언어 오류율 대비 최대 14배 증가함을 보이고
- 합성 데이터를 활용하여 이러한 문제를 저비용으로 어느 정도 완화할 수 있음을 보였습니다.
🤔 코드 스위칭이란?
우리 말로는 말씨 바꾸기라고도 하는 코드 스위칭(Code-Switching; CS)은, 한 대화나 맥락에서 여러 개의 언어를 바꿔가며 구사하는 것을 이야기합니다. 우리가 흔히 판교어라고 부르는 IT 전문용어(영어)와 한국어를 섞어 말하는 말투도, 대표적인 코드 스위칭이라고 할 수 있죠!
"Hey, Gio, 오늘 아침에 dev branch 오류 관련해서 issue 남긴 거 봤어요?"
같은 언어를 사용하는 사람들과 생활할 때는 이러한 코드 스위칭을 흔히 접하지 않지만, IT나 의료 분야와 같이 외국 전문용어의 유입이 활발한 분야에 대하여 소통하거나, 외국어를 배울 때, 또는 습관적으로 여러 언어를 섞어 사용하는 다국어 구사자의 경우, 코드 스위칭을 일상적으로 구사하게 됩니다.
💭 다양한 형태의 코드 스위칭
이러한 코드 스위칭은 혼용되는 언어 쌍에 따라 다양한 형태로 나타날 수 있는데요. 명사나 형용사, 동사 등 하나의 단어를 다른 언어로 치환하는 단어 단위의 코드 스위칭(word-level CS)부터, 문장 내에서 여러 부분을 다른 언어로 치환하는 구 단위의 코드 스위칭(phrase-level CS), 그리고 여러 문장을 각기 다른 언어로 사용하는 문장 단위의 코드 스위칭(sentence-level CS)까지 다양한 코드 스위칭의 형태가 존재합니다. 음성 인식의 관점에서, 각 유형의 코드 스위칭은 각기 다른 특성을 갖는데요.
문장 단위의 코드 스위칭은 언어가 바뀌는 코드 스위칭 지점(CS point)이 문장 간의 경계에서만 발생하여, 비교적 규칙적인 특징을 갖습니다.
"그 부분은 저희 팀원이 조금 더 잘 설명할 수 있을 것 같은데요. Shawn, will you explain this?"
반면에, 단어 단위 또는 구 단위의 코드 스위칭은 문장 내 어디에서든 코드 스위칭이 발생할 수 있어, 불규칙적이고 코드 스위칭 지점도 더 많은 특징을 갖습니다.
"선생님, 'should have'하고 'would have' 차이가 뭔지 전혀 모르겠어요."
특히, 구 단위의 코드 스위칭의 경우 한국어와 영어와 같이 문법 체계가 다른 언어 쌍에서는 복잡한 문법 구성이 발생하게 되어 AI 모델은 물론 사람조차도 어려운 특이한 경우가 탄생하기도 하죠.
"빙빙 돌려말하지 말고 get to the point로 말 해봐. You know what I'm talking about?"
이러한 코드 스위칭은 영어나 한국어 하나의 언어만을 사용하는 사람들에게는 크게 중요하지 않지만, 영어 전문 용어를 일상적으로 사용하는 분야에서 일하거나, AI 기반 영어 교육을 필요로 하는 사람, 혹은 2개 국어를 구사하여 자연스럽게 코드 스위칭을 사용하는 사람들에게 있어서는 코드 스위칭 발화를 정확히 인식하는 기술이 반드시 필요합니다.
✨ HiKE: 최초의 한-영 코드 스위칭 벤치마크, 그런데 심층적인 분석을 곁들인...
세타원 AI는 그동안 연구되지 않았던 음성인식(ASR) 모델의 한국어-영어 코드 스위칭 인식 능력을 평가하기 위해, 세계 최초의 한국어-영어 코드 스위칭 음성인식 평가 프레임워크인 HiKE를 개발하였습니다.
HiKE는 Hierarchical Korean-English Code-Switching Benchmark의 약자로, 앞서 설명 드렸던 3가지 코드 스위칭 형태에 따라 음성인식 모델의 인식 성능을 정밀하게 평가할 수 있습니다.
기존에는 음성인식 모델의 코드 스위칭 성능을 객관적으로 평가할 방법이 없어 수집하기 어려운 코드 스위칭 데이터를 자체적으로 수집하거나, 검증되지 않은 음성인식 모델을 사용해야 했으나, 이제는 모델의 성능을 객관적으로 비교하고, 개선할 기준점이 생긴 것이죠!
다양한 주제, 현실적인 코드 스위칭 음성 데이터
서비스에 필요한 모델의 성능을 검증하고 평가하기 위해, HiKE의 음성 데이터는 실제로 코드 스위칭이 흔하게 사용되는 8가지 주제를 바탕으로 수집되었습니다.
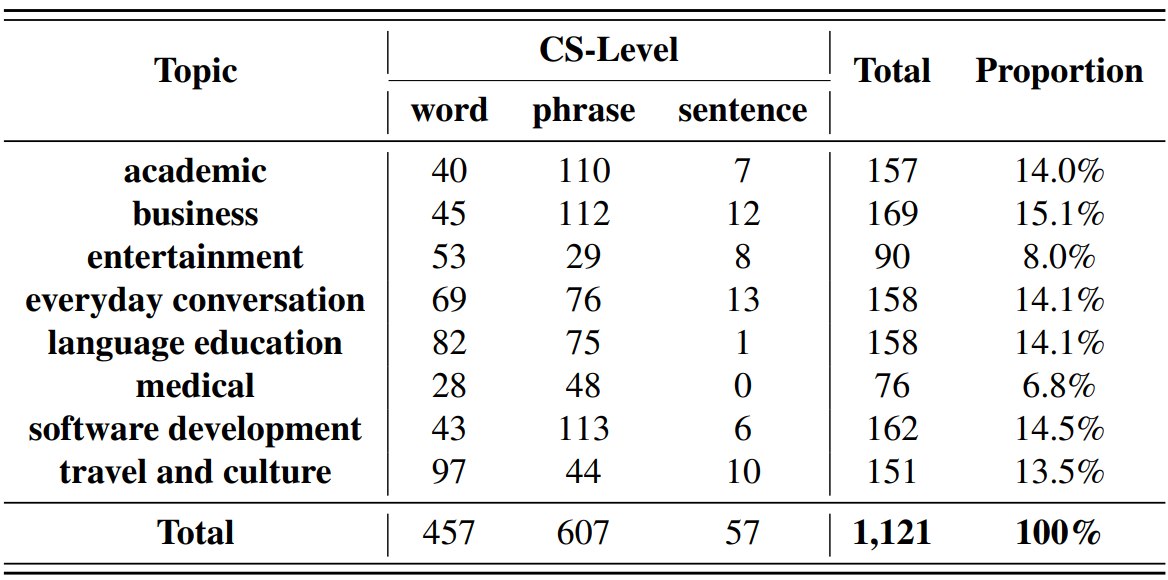
수집된 2.2시간 분량의 샘플들을 주제와 코드 스위칭 형태에 따라 위와 같이 분류하여, 실제로 요구되는 코드 스위칭 상황에 대한 성능을 정확하게 측정할 수 있도록 하였습니다.
코드 스위칭 음성인식을 위한 평가 지표
단일 언어에서의 음성인식 정확도는 주로 문자 단위 오류율(Character Error Rate; CER) 또는 단어 단위 오류율(Word Error Rate; WER)을 활용하여 평가하는데요. 한국어와 같이 음절 구조가 복잡하고 띄어쓰기 오류가 잦은 언어에서는 문자 단위 오류율(CER)이, 영어처럼 명확하게 단어 경계가 구분되는 언어에서는 단어 단위 오류율(WER)이 주로 사용됩니다.
한편, 한국어와 영어가 모두 사용되는 코드 스위칭에서는 이러한 지표 한 가지만을 사용하면 정확한 성능을 측정하기 어려울 수 있는데요, 저희는 정밀한 성능 평가를 위해 **혼합 오류율(Mixture Error Rate;MER)**과 **관심영역 오류율(Point of Interest Error Rate;PIER)**을 사용하여 모델들을 평가하였습니다.
혼합 오류율(MER)은 한국어 영역은 문자 단위로, 영어 단위는 단어 단위로 오류율을 계산하여 평가를 진행하는 지표입니다. 이를 통해, 음성인식 결과 전반의 정확도를 평가할 수 있습니다.
한편, 관심영역 오류율(PIER)은 평가자가 원하는 영역에서만 오류율을 측정하는 지표인데요, 코드 스위칭 분야에서 코드 스위칭이 일어나는 영역을 지정하여, 모델이 언어가 바뀌는 순간을 잘 감지하는가를 평가하는데 활용됩니다.
<tag 이번> <tag bug> <tag 는> <tag session> management <tag logic> <tag 에> 문제가 있었어
예를 들어, 위 문장에서 tag가 지정되어 있는 코드 스위칭이 발생하는 앞 뒤 영역만을 집중적으로 평가하는 것이죠!
두 지표를 함께 활용하여, 모델의 전반적인 음성인식 정확도와 코드 스위칭 지점에서의 음성인식 정확도를 각각 평가할 수 있습니다.
평가 결과
| # Params | MER | PIER | Monolingual | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Word | Phrase | Sentence | Overall | Word | Phrase | Sentence | Overall | KOR | ENG | ||
| SenseVoice-small | 234M | 29.3 | 37.9 | 26.8 | 33.9 | 53.9 | 56.6 | 38.8 | 54.6 | 6.4 | 7.6 |
| Whisper Tiny | 38M | 78.8 | 128.7 | 39.1 | 103.8 | 89.1 | 76.4 | 68.5 | 81.2 | 11.9 | 14.6 |
| Whisper Base | 74M | 124.7 | 84.2 | 28.3 | 97.8 | 92.2 | 76.5 | 42.4 | 81.2 | 7.8 | 9.8 |
| Whisper Small | 244M | 59.2 | 46.0 | 20.6 | 50.1 | 69.3 | 46.7 | 31.6 | 55.2 | 4.5 | 8.3 |
| Whisper Medium | 769M | 44.6 | 33.6 | 17.9 | 37.3 | 40.6 | 51.7 | 31.1 | 46.1 | 3.4 | 4.6 |
| Whisper Large | 1.5B | 30.6 | 23.5 | 12.3 | 25.8 | 43.7 | 28.9 | 18.9 | 34.4 | 3.2 | 4.4 |
| Seamless | 2.3B | 115.0 | 71.7 | 65.1 | 89.0 | 78.1 | 64.7 | 58.2 | 69.8 | 6.4 | 6.3 |
| Audio Flamingo 3 | 8.3B | 79.2 | 83.7 | 80.8 | 81.7 | 102.2 | 98.2 | 116.0 | 100.7 | 25.1 | 6.4 |
| GPT-4o | N/A | 17.8 | 27.1 | 27.5 | 23.3 | 25.9 | 30.8 | 33.5 | 28.9 | 2.5 | 3.3 |
Theta One STT ✨ 2025.07 | N/A | 18.6 | 22.5 | 9.0 | 20.2 | 28.5 | 30.4 | 10.4 | 28.6 | ||
저희는 코드 스위칭에 강건한 구조로 알려진 CTC 기반의 모델 SenseVoice Small부터, 가장 대중적으로 사용되는 고성능 다국어 음성인식 모델인 Whisper, 고성능 대규모 언어 모델(LLM) 기반 모델인 Audio Flamingo3 (NVIDIA)와 GPT-4o (OpenAI)까지 다양한 다국어 지원 음성인식 모델을 평가하였습니다. 그 결과, 대부분의 모델이 한국어나 영어 단일 언어에서는 대체로 좋은 성능을 보여주었음에도 불구하고, 두 언어가 혼용되는 코드 스위칭에서는 MER과 PIER 모두 3-14배에 달하는 오류 증가폭을 보임을 알 수 있었습니다.
특히, 각 문장은 하나의 언어로 구성되고, 코드 스위칭이 문장 간의 경계에서만 발생하는 문장 수준 코드 스위칭보다도 현실 상황에서 더 많이 발생하는 단어, 문단 수준의 코드 스위칭에서 오류율 증가가 큰 모습을 많은 모델에서 확인할 수 있었는데요. 이는 영어나 한국어 성능이 뛰어나다고 하더라도, 실제 서비스에 음성 인식 모델을 적용할 경우 치명적인 사용자 경험 악화로 이어질 수 있음을 시사합니다.
논문과 별도로, 저희가 개발한 Theta One STT 모델(버전 2025.07)도 평가하였는데요, MER과 PIER에 있어 대규모 모델인 GPT-4o 보다도 낮은 오류율을 보여주는 것을 확인할 수 있었습니다.
업계 유일의 아동 음성인식, 한-영 코드 스위칭 음성인식을 지원하는 Theta One STT는 지금 Theta One AI 콘솔에서 이용하실 수 있습니다.
합성 데이터를 통한 한-영 혼용 음성인식 성능 개선
이렇듯 대부분의 모델이 한-영 코드 스위칭 환경에서는 도저히 사용할 수 없을 정도로 높은 오류율을 보여주는 상황에서, 코드 스위칭 성능을 개선하기 위해서는 어떤 방법이 있을까요?
실제 사람으로부터 충분한 양의 코드 스위칭 음성 데이터를 수집하여 모델을 파인튜닝할 수 있다면 가장 좋겠지만, 이러한 희귀 데이터의 수집에는 적지않은 비용과 노력이 수반되기 마련이죠. 따라서 저희는 비교적 수급이 쉬운 한국어, 영어 단일 언어 데이터를 이어 붙여서 만든 합성 문장 단위 CS 데이터(Synthetic Sentence-Level CS Data)를 구하기 어려운 실제 데이터 대신 사용하여 파인튜닝하는 방법을 고안하였습니다.
| MER | PIER | Monolingual | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Word | Phrase | Sentence | Overall | Word | Phrase | Sentence | Overall | KOR | ENG | |
| Whisper-Medium | 50.1 | 27.3 | 45.1 | 37.5 | 71.0 | 33.3 | 42.1 | 49.1 | 3.4 | 4.6 |
| (a) 실제 데이터에서 파인튜닝 | 9.9(-34.7) | 10.3(-23.3) | 8.0(-9.9) | 10.0(-27.3) | 19.8(-20.8) | 19.1(-32.6) | 22.7(-8.4) | 19.5(-26.6) | 6.0(+2.6) | 5.2(+0.6) |
| (b) 합성 데이터에서 파인튜닝 | 21.0(-23.6) | 27.6(-6.0) | 7.5(-10.4) | 23.9(-13.4) | 33.0(-7.6) | 32.9(-18.8) | 16.0(-15.1) | 32.1(-14.0) | 3.7(+0.3) | 5.1(+0.5) |
| (a) + (b) 실제와 합성 데이터 모두 활용 | 22.6(-22.0) | 22.7(-10.9) | 6.0(-11.9) | 21.8(-15.5) | 27.9(-12.7) | 36.9(-14.8) | 13.5(-17.6) | 32.0(-14.1) | 3.9(+0.5) | 4.9(+0.3) |
파인튜닝한 모델을 HiKE 벤치마크로 평가한 결과, 놀랍게도 합성 데이터를 사용한 파인튜닝에서도 MER과 PIER가 큰 폭으로 개선되는 것을 알 수 있었습니다. 비록 실제 데이터를 사용하여 파인튜닝한 모델(a)에는 미치지 못 하지만, 적은 비용으로 PoC를 진행하는 단계에서는 단순한 이어 붙이기(concatenation) 기법으로 생성한 합성 데이터도 충분히 도움이 된다는 것이죠!
코드 스위칭은 물론 아동 음성인식까지! 세타원 STT
모델 학습의 산을 넘었다고 하지만, 실제 서비스에 STT를 응용하기 위해서는 아직 많은 고비가 남아있습니다.
모델이 단순히 벤치마크 점수를 넘어, 실제 서비스에서 잘 동작하는지 평가하기 위한 지표 설계, 효율적인 배포를 위한 경량화, GPU 배포 플랫폼 등 개발적인 노력은 물론 높은 호스팅 비용까지 감당해야하죠.
세타원은 코드 스위칭은 물론, 세계에서 유일하게 아동 음성인식까지 지원하는 고성능 STT 모델을 API 형태로 서비스하고 있으며, 지금 이 순간에도 모델 정확도와 속도를 개선하기 위한 연구와 개선이 이루어지고 있습니다.
지금 https://console.thetaone.co/ 에 접속하셔서 세계 최고 수준의 음성인식 AI를 합리적 가격에 이용해보세요!
읽어주셔서 감사합니다!
